


Interline now offers OSM Extracts, a service enabling software developers and GIS professionals to download chunks of OpenStreetMap data for 200 major cities and regions around the world.
OSM Extracts is simple. It’s a 3 step process that you can run yourself. We’ll describe these steps, as well as how we run those 3 steps for all 200 extracts in parallel on Interline’s cloud infrastructure.
Creating OSM Extracts in 3 steps
Every day at Interline our servers download the latest updates from OpenStreetMap, update our local copies of the planet file, and process this data to generate a variety of geospatial data products. Reliably updating a planet file requires a bit of legwork behind the scenes, which we have encapsulated as helper scripts in our PlanetUtils library. This simplifies the process down to 3 steps:
- Run
osm_planet_updateto download the most recent OSM planet file (released weekly at planet.openstreetmap.org and other mirrors) and then apply minutely “diffs” to update the planet file to the current point in time. - Fetch a copy of cities.json file from GitHub. This GeoJSON file contains polygons defining the boundaries of each extract, and is a continuation of the extract definitions created by over 100 contributors for the Mapzen Metro Extracts service. The file is open to additions and revisions by all.
- Run
osm_planet_extract, specifying the local copy of the cities.json file, to generate extracts for each of the cities/regions.
Behind the scenes, PlanetUtils handles calls to osmosis and osmconvert to update the planet and generate the extracts. For more information on each of these commands, see the PlanetUtils readme, or install the package yourself using Homebrew or Docker.
This workflow is simple but slow. Updating the planet and generating all 200 extracts on a single machine can take more than a day. In addition to the extracts, the updated planet is the starting point for additional data products, such as our Valhalla Tilepacks. Valhalla Tilepacks combine the OSM planet file with 1.6Tb of elevation data to produce downloadable data for organizations to run their own instances of the Valhalla routing engine. All of this heavy lifting requires a substantial mix of computing resources. Parallel workflows to the rescue!
Managing our OSM Extracts workflow
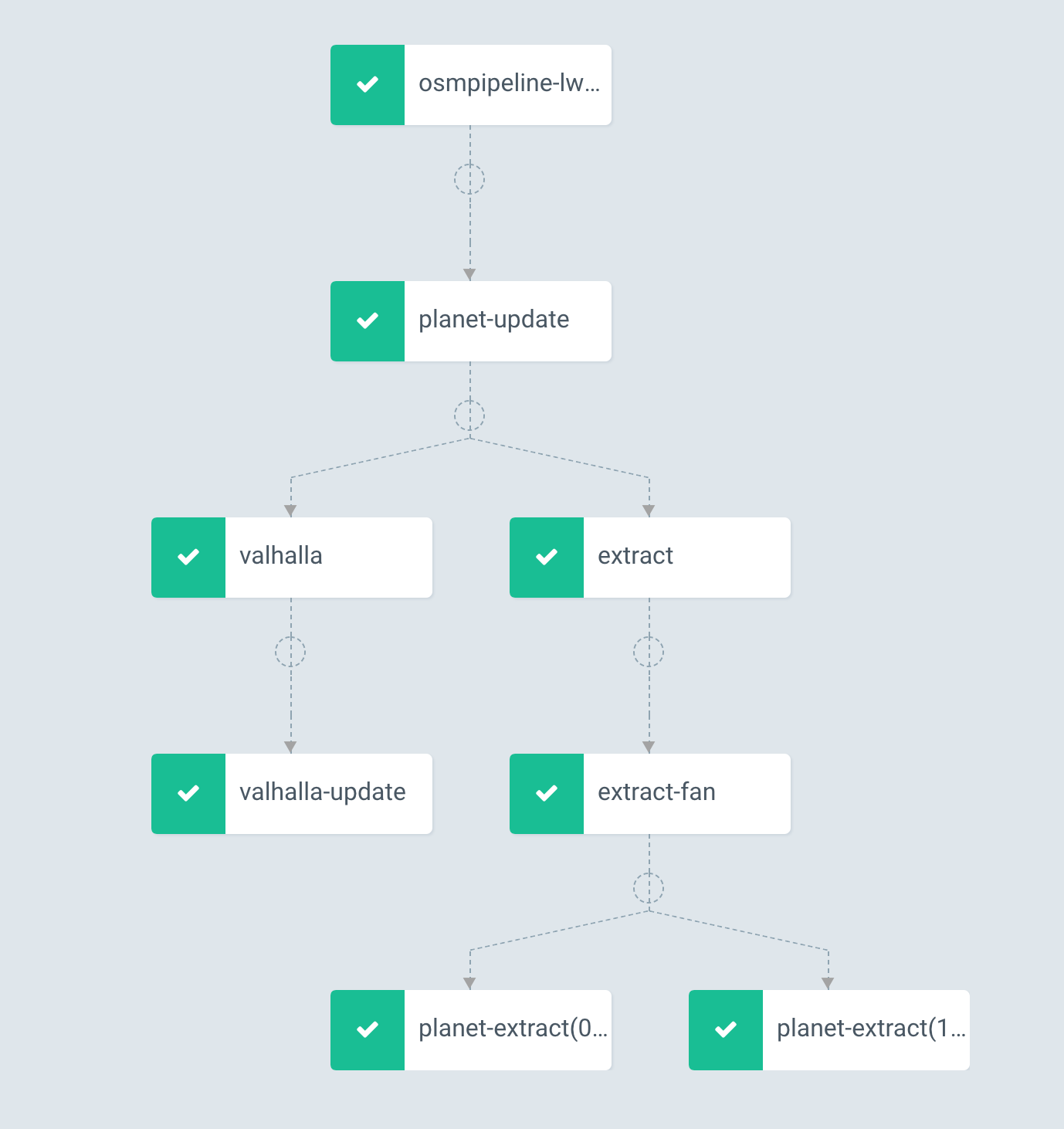
At Interline, we have a great appreciation for Kubernetes which powers much of our infrastructure. Kubernetes is ideal for running highly available services and managing complex resources. We wanted our data workflow system to leverage this infrastructure and introduce as little additional complexity as possible. With these constraints, we found that Argo Workflow Manager was a great fit for our needs:
- Each Argo workflow step is a Kubernetes pod and Docker container, simplifying resource requests and access to secrets (e.g., passwords and access keys for external services).
- Workflows can be described as a directed graph, with an easy syntax for specifying dependencies between steps.
- Argo provides a flexible method for specifying output files and parameters that can be fed into subsequent steps.
- Parallel workflows are well supported, and one step can “fan out” to a number of parallel tasks (as you can see in the diagram above).
Our Argo workflow resembles the simple 3-step process with a few key adjustments:
- Update our local planet using
osm_planet_updateand copy to our cloud storage bucket. - Fetch the
cities.jsonfile, and divide the GeoJSON features into smaller chunks of about 8 extracts each. - Run each chunk as a parallel task to quickly generate all 200 extracts.
Because each Argo task is defined as a Kubernetes pod, we have very fine-grained control over the resources allocated to each task. The Kubernetes scheduler is very effective at auto-scaling your cluster based, quickly increasing cluster size to run all tasks in parallel, and just as importantly, reducing the cluster size when the tasks are complete. Additionally, because some tasks are CPU intensive and others are memory intensive, we define multiple node pools to ensure a high utilization of cluster resources.
Currently, we run about 25 tasks of 8 extracts each. With each task requesting an 8 CPU node, generating all 200 extracts in parallel takes about 35 minutes. This workflow also allows us to run multiple data pipelines together, sharing common outputs and reducing the amount of work that has to be duplicated. For instance, the updated planet file generated in the first step above is also used as the input to our Valhalla workflow.
Next steps in the workflow
Our strategy for working with OpenStreetMap and other data sources is “snout to tail” — that is, we look for opportunities to turn each piece of a giant data download into a useful “meal” for users. We’re working on additional inputs and outputs to Interline’s workflow. Tuning the workflow is also always a work in process. Each week, we find more ways to improve the performance of a step. We look forward to sharing more updates on our workflow in the future.
In the meantime, we’d like to invite you to add a few next steps to your “professional workflow”:
- If you work with OpenStreetMap data, sign up for the free OSM Extracts developer preview.
- If your organization needs to deploy a worldwide routing engine on premise or its in own cloud account, evaluate Valhalla Tilepacks.
- If your organization runs its own custom data workflow and needs help consider these or other workflow approaches, contact us to discuss Interline’s consulting service. We’re glad to share our experiences with Argo, Kubernetes, and related technologies.


