

At Interline, we specialize in deploying, creating, and managing the growth of open-source software. It’s less an individual matter of principle than a set of shared advantages: our clients build on each other’s advances, and we collaborate productively with a wide range of partners. However, the health of an open-source project is not a given — it requires ongoing attention and thought. In this blog post, we’ll share an overview of practices used by a wide variety of open-source projects:
Useful practices
- 👍 Clean licenses
- 👍 Technical steering committees
- 👍 RFC (request for comments) processes
- 👍 Feature flags
- 👍 “Contrib” vs. core
- 👍 Automated acceptance test and performance suites
- 👍 Automated dependency checks
- 👍 Release management
- 👍 Codes of conduct
Unclear practices
Bad outcomes
OpenTripPlanner: An open-source project going on 10 years
This blog post comes out of a presentation Interline gave at last month’s OpenTripPlanner Summit in Boston. None of the practices are particular to that project. However, some background will help explain how relevant many of these open-source practices are to OpenTripPlanner and similar open-source projects that have become critical — but also somewhat neglected — pieces of infrastructure for many organizations.
The OpenTripPlanner routing engine (also known as OTP) was created in 2009 by TriMet (the public-transit agency in Portland, Oregon), OpenPlans (a civic tech non-profit), and individual experts and enthusiasts. Since then, OTP has grown to be used by public-transit agencies, planning firms, and transportation researchers around the world. (Interline itself provides managed hosting of OTP for a variety of public-transit agencies around North America.)
And yet the OTP project rests on an unstable foundation. Many individuals and organizations contribute to developing new features and expanding OTP’s reach, but few are involved directly in maintenance, coordination, and the other “housekeeping chores” of an open-source project.
One outcome of last month’s OpenTripPlanner Summit is that more organizations will be collaborating on this “housekeeping.” Interline is joining the OTP Project Leadership Committee, alongside Cambridge Systematics, Conveyal, TriMet, Ruter (the public-transit agency of Oslo), the University of South Florida, the PlannerStack Foundation, and the Helsinki Regional Transport Authority.
Now, with this context in mind, let’s zoom out and consider a wide range of practices that complex and collaborative open-source projects use to grow and thrive.
Clean licenses
Choosing a (single) license
At the core of an open-source project is its license. This is what legally enables use and contribution to the project by many individuals and organizations. The Open Source Initiative catalogs hundreds of licenses and highlights a short list of the most popular options:
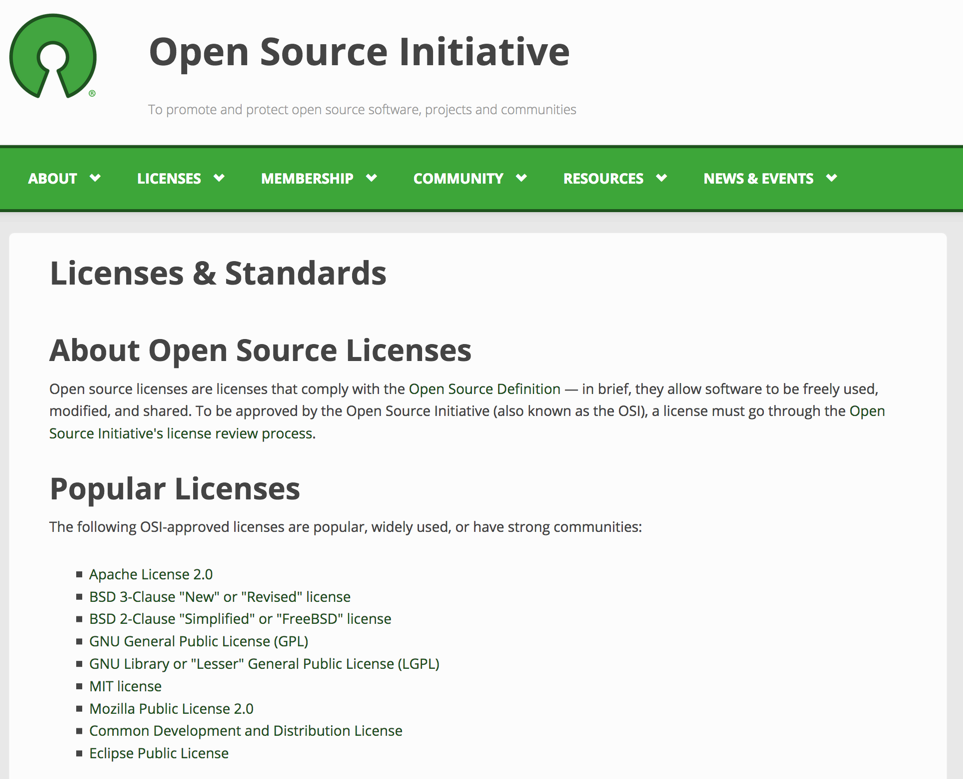
Different licenses can encourage different outcomes. OpenTripPlanner uses the LGPLv3 license, which requires that any organization directly customizing OTP code publicly share their changes. However, the LGPLv3 license does allow organizations to use OTP within the context of larger proprietary systems.
Using dual licenses
Some projects are released under dual licenses. For example, the Sidekiq project is available for free under LGPLv3. Organizations that require more flexibility (for example, to customize code and keep their changes private), may pay the primary creator of Sidekiq for an alternative license:
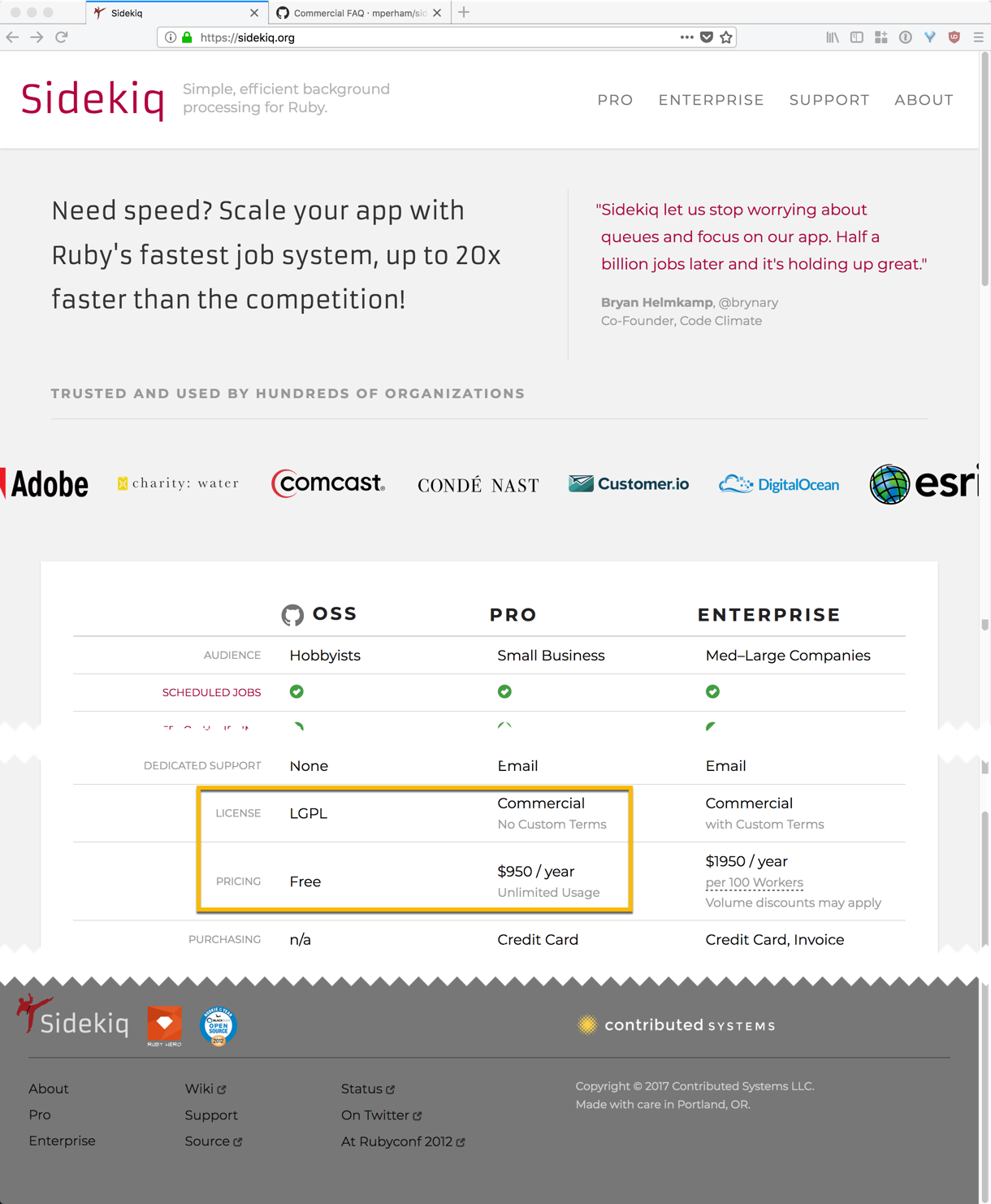
The dual license model can have trade-offs. It may provide resources to build a business around an open-source project, and it may provide a predictable means for buying support for large users. However, it can be off-putting or at least confusing to smaller users who assume “open-source = completely free.” Clear communication is important. Consider the case of the ExtJS project, which switched to a dual license in 2008, alienating many of its users.
Contributor license agreements
The presence of a license file in an open-source code repository is a meaningful signal, but it isn’t always sufficent reassurance to businesses that the code is free of legal risk. Some open-source project sponsors ask all contributors to sign a contributor agreement before their code is merged into the open-source project. Typically, these agreements ask the “signer” to say that they personally created whatever code it is that they are contributing and that they are not knowingly contributing materials for which they don’t hold rights. Some contributor agreements go further, asking contributors to sign over intellectual property rights to the primary company that maintains the project. At a minimum, such an agreement provides all companies involved with some reassurance that contributors aren’t intentionally adding others’ code or private materials.
The Linux Foundation no longer recommends broad contributor agreements; instead they offer the simple Developer Certificate of Origin.
Open-source projects that do need to enforce one of these agreements can add a “bot” to GitHub or a similar source-code repository. Here’s a bot to enforce the Developer Certificate of Origin and a bot to enforce a custom contributor license agreement:
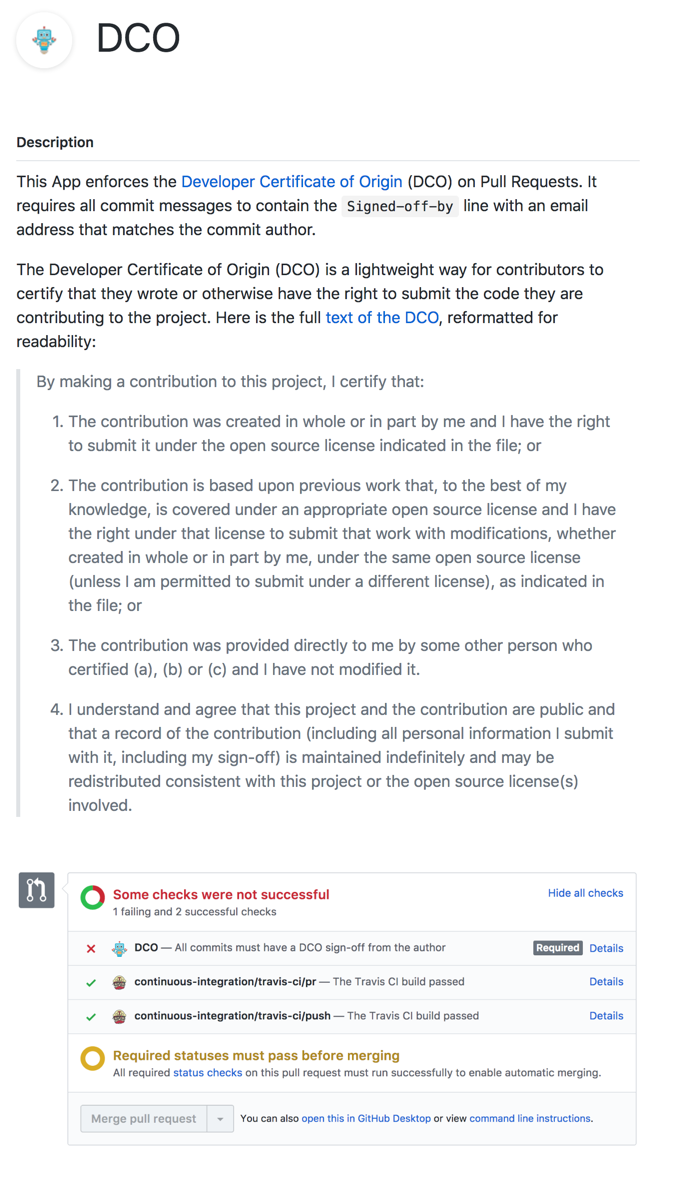
Code licenses and contributor license agreements are necessary but not sufficient for an open-source project to succeed. They set the incentives and the bounds for collaboration and growth.
Technical steering committees
Licenses allow contribution, but who will accept the contributions? Many projects appoint a technical steering committee (or TSC) to make such decisions.
For example, here are the responsibilities of the Node.js TSC:
- Managing code and documentation creation and changes for the listed projects and resources
- Setting and maintaining standards covering contributions of code, documentation and other materials
- Managing code and binary releases: types, schedules, frequency, delivery mechanisms
- Making decisions regarding dependencies of the Node.js Core project, - including what those dependencies are and how they are bundled with source code and releases
- Creating new repositories and projects under the nodejs GitHub organization as required
- Setting overall technical direction for the Node.js Core project, - including high-level goals and low-level specifics regarding features and functionality
- Setting and maintaining appropriate standards for community discourse via the various mediums under TSC control
- Setting and maintaining governance rules for the conduct and make-up of the TSC, Working Groups and other bodies within the TSC's domain
The history of the Node.js TSC is useful to consider. Development of Node.js had nominally been overseen by a single company, named Joyent. When outside contributors to the project found their contributions and their specific technical needs not addressed by Joyent staff, they forked the Node.js code (that is, they copied the code) and started a new effort. This new project, called io.js, was formed around a TSC and an “open” governance process. After much negotiation, Joyent and the io.js TSC combined their efforts under the newly formed Node.js Foundation. The code improvements made by this “splinter” effort found their way back into the Node.js code base. More importantly, the new governance structure continued.
Consider another example: the OneBusAway project. It’s governed by a steering committee that is structured to include a mix of representatives from the private sector, the public sector, universities, and independent individuals.
As these two examples demonstrate, the primary challenge of a TSC is ensuring that it has an appropriate representation across the open-source project’s contributors and users. If a TSC has too few members or members that are only concerned with low-level software development concerns, the project will miss opportunities to learn from less technically sophisticated users. Alternatively, with a TSC that is too broad and includes individuals or organizations that are not deeply invested in the project, the risk is that the TSC will have many ideas but little action.
RFC (request for comments) processes
Technical steering committees (TSCs) can put thoughts into actions by various means. Let’s look at the RFC (that is, request for comments) process now. Later on, we’ll also consider the ”roadmap“.
The Internet and its protocols were created and continue to mature using RFCs. RFCs are documents that put into words all of the ingredients of a proposed technical change. They are both speculative and precise. They are always pedantic (many RFCs begin by defining exactly what the authors mean by “must” and “must not”) and sometimes humorous (well, humorous in the eyes of fellow engineers). An RFC is a structured format for proposing new software development and honing plans based on feedback.
The Rust programming language has a well defined RFC process; it’s been used as a model by many other open-soure projects. For the Rust project, contributors must write an RFC for:
- Making “Substantial changes” that are not bug fixes
- Removing existing features
- Changing interfaces between components
RFCs are not required for:
- Refactoring, reorganizing
- “Additions that strictly improve objective, numerical quality criteria (warning removal, speedup, better platform coverage, more parallelism, trap more errors, etc.)”
- “Additions only likely to be noticed by other developers-of-rust, invisible to users-of-rust.”
When drafting a new RFC, contributors are asked to include:
- Summary (one paragraph)
- Motivation
- “Guide-level explanation”: features, API input/output, example use-cases
- “Reference-level explanation”: technical implementation details
- Drawbacks: “why should we not do this?”
- Rationale and alternatives
- Why is this design the best in the space of possible designs?
- What other designs have been considered? What is the rationale for not choosing them?
- What is the impact of not doing this?
- Prior art
- Unresolved questions
An RFC process front-loads the collaborative work of major changes or additions to an open-source project. That is, instead of waiting until a pull request arrives with lines of code changes, discussion begins early. Contributors are required to put in effort up-front to help others in the project community understand their proposed changes. The project’s TSC and its extended developer community are invited to provide input within the structure of the RFC.
RFCs do introduce more overhead to a project. A developer can no longer just assume a code contribution speaks for itself; they do also have to put their ideas into words and arguments. However, the RFC process is often a net gain for open-source projects of a certain size and complexity. Any individual or organization is invited to contribute to the project’s growth — they are just asked to work within a structure.
Feature flags
Once an RFC has been “green lighted” by a TSC (or whatever approval critiera is used on a particular project), there are the questions of when and how to merge the related code changes and additions into the project. The sooner code is merged, the easier it will be for others to test and integrate with their own work-in-progress. The later code is merged, the more polished it may be. However, there is also the unfortunate reality of open-source development: The sooner code is merged, the more likely it will introduce bugs and needlessly expand future “surface area” requiring maintenance. The later code is merged, the more likely the developer will disappear, having lost interest in seeing their contribution reach fruition.
One practice that strikes a balance between “too soon” and “too late” is to use feature flags. New additions are merged into a code base before they are ready for general use. Users can only access one of these new features by setting a configuration “flag” to opt-in. Feature flags provide a means to stage the introduction of major changes and additions. Code changes are merged early and often; functionality changes are hidden from most users until later.
The feature-flag practice is also used within many web sites and applications. Facebook selectively rolls out feature changes to certain numbers and types of users, much like how junk food manufacturers test their new sodas and chips in small but representative markets.
The EmberJS project uses feature flags together with an RFC process. Each RFC typically turns into code hidden behind a feature flag. Advanced users can opt-in to the feature in early releases. After further testing and improvement, the feature flag will be removed and all users will use that code in future releases. (Later, we’ll also discuss release management, which helps pace this process of introducing new functionality to a wider audience.)
“Contrib” vs. core
RFCs and feature flags work for contributions that are relevant to all users of a project, but what if a contribution is only relevant to some? An alternative approach is to divide an open-source project into two zones: “core” and “contrib” (that is, contributed). The standards for acceptance for changes to “core” are high — everyone depends on the stability and performance of these components. The standards for “contrib” are lower — these components may offer expanded functionality, but they come with fewer promises of current performance and future maintenance. “Contrib” is an area for experimentation, while “core” is more carefully managed through RFCs and similar types of structure.
Here’s how the Drupal CMS differentiates between its core and contributed modules:

Note how Drupal also refers to custom modules. In the case of OTP, the reason for our OpenTripPlanner Summit last month is that many potential code contributions to OTP have been accumulating in branches and forks, but few are being merged back into the main OTP repository’s master branch. In effect, these branches and forks are all custom modules — without a clear path to entry to a “contrib” or a “core.”
To succeed, the core/contrib split does require certain conditions. First, the open-source project must be modular and expandable. That is, “contrib” code should be able to extend or modify aspects of “core” code. Otherwise, all changes would need to happen directly within “core.” (This is a challenge for many projects, OTP included.) Second, “contrib” is a poor shorthand for “code developed by non-core committers.” The core/contrib split is best used as a dividing line between the level of commitment a project has to certain functionality, rather than a dividing line between classes of developers.
Automated acceptance test and performance suites
Whether code is going behind a feature flag, into “core”, or into “contrib,” there should be a process for verifying its quality before it is merged. This is important in any type of software development effort; it’s especially important for open-source development, where contributions may be coming from developers of various skill levels, using various tools and development environments.
Many open-source projects require that new code contributions also come with automated tests. These tests use sample data and conditions to demonstrate that new functionality behaves as expected. Automated tests help prevent regressions (a future change breaking current functionality). Tests also help document functionality, for other developers to understand a system’s goals.
There are many types of software tests: unit tests, integration tests, smoke tests, GUI testing, performance testing, security vulnerability scanning, and accessibility testing. The specific test types will depend on the type of project. Different mixes of testing approaches are useful for command-line interface scripts, web applications, mobile applications, desktop GUIs, or embedded system modules.
An open-source project should aim to run automated tests for two overall goals: acceptance and performance. An acceptance test suite tells developers that a proposed code change works as expected and doesn’t break existing functionality. A performance test suite warns developers when proposed code changes will have dramatic changes on speed or resource consumption. For some systems, a single set of tests can inform both acceptance and performance. For other systems, acceptance and performance are more easily tested as separate steps, before and after the piece of software is built or compiled.
Acceptance and performance tests can be automatically run against every proposed code change by a build/CI/CD server. (CI stands for continuous integration; CD stands for continuous delivery.) We especially like CircleCI at Interline, and will be blogging more about this soon.
Acceptance and performance tests often produce a green ✅ or a red ❌ — that is, they give a “yes” or “no” answer to the question of whether a proposed code change is good to merge. However, good test suites also produce more detailed information for ongoing use by a TSC and the regular contributors to an open-source project.
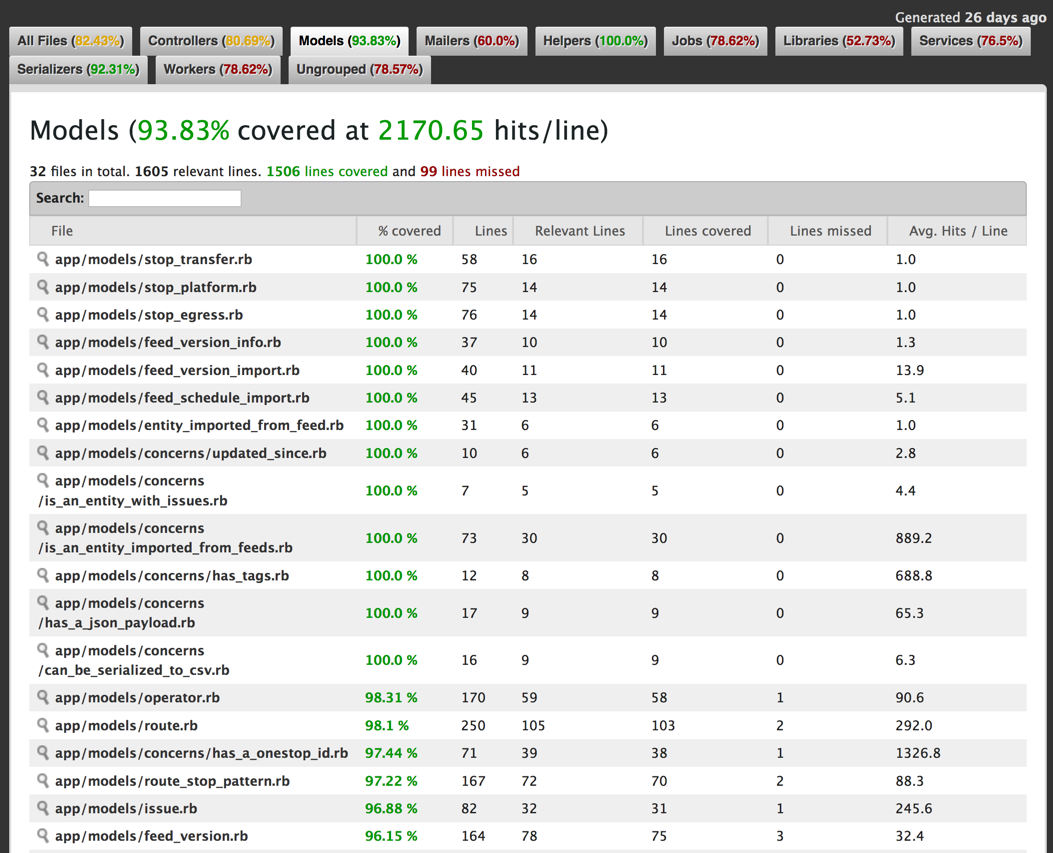
Here’s a code coverage report for the Transitland Datastore, the web application at the center of the Transitland open public-transit data platform. This report is generated by the acceptance test suite. We occasionally review it to ensure that acceptance tests are covering a growing portion of the code bases:
For programming languages and other heavily used software infrastructure, small differences can make major unexpected performance differences. The RubyBench project regularly evaluates hundred of actions in the Ruby scripting language and its most important packages. The same tests are run against new releases, enabling comparison with past versions. Developers can use the website to, hopefully, see performance increasing over time:
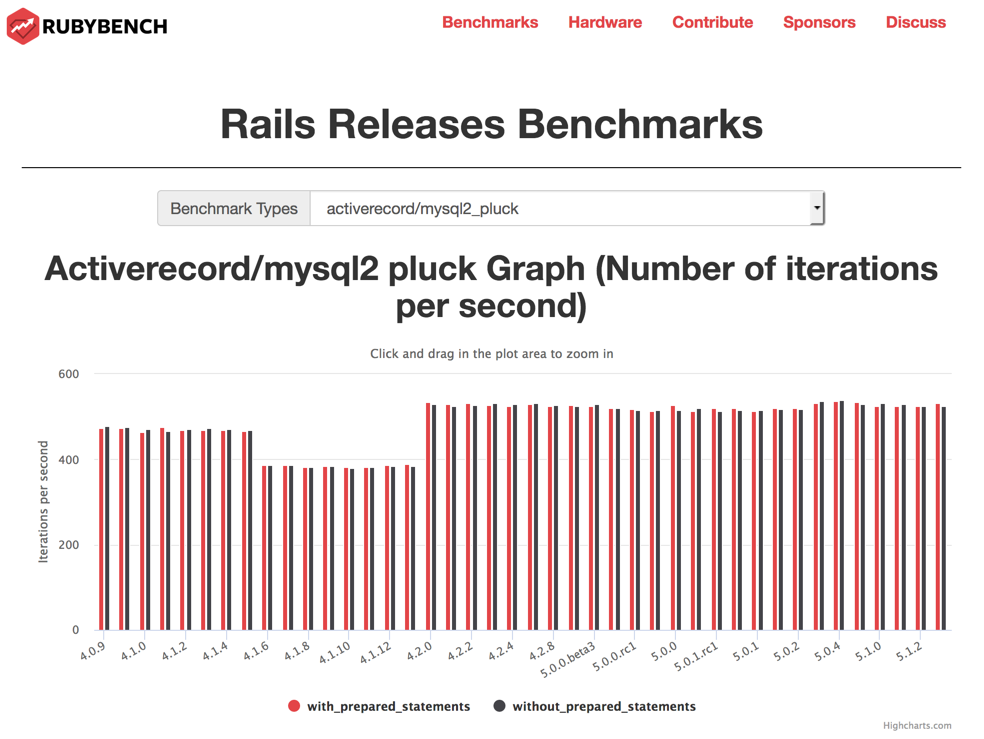
All software projects benefit from testing infrastructure. Testing infrastructure that is easy to access and use is all the more important for open-source software. Learning to read and write tests is an important step in the education of a software engineer. For some, an open-source project will be the first time they encounter auomated test infrastructure. Even for experienced developers, seeing their proposed change produce the red ❌ of a failing change may be the first occasion they have to dig deeply into an unfamiliar code base.
Writing and running tests does not need to feel like flossing, a boring but necessary chore. When test suites are well structured and made easily accessible, testing helps improve everyone’s confidence in an open-source project and to reduce the risk of contributing.
Automated dependency checks
Most pieces of open-source software are built upon others. These are software dependencies. Sometimes, dependencies are just copies of code. Hopefully, dependencies are included using a package manager. Package managers make it simple to upgrade dependencies, when new versions are released.
Just as open-source projects benefit from making automated test suites accessible to developers, projects can benefit from automating and making accessible the process of checking for new dependencies.
Here’s an email I received a while back from a service called Gemnasium, reporting that a new version of a dependency is available and fixes a known security vulnerability:
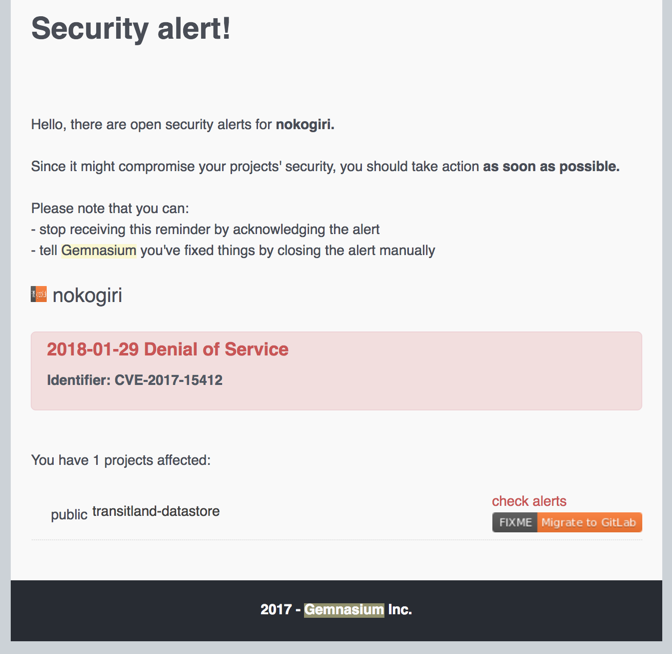
Gemnasium has now been acquired by Gitlab, where they are beginning to offer a similar automated service. GitHub now also offers its own dependency updates. Some services, like Greenkeeper, will even perform updates automatically, without waiting for a developer to do so on their own computer.
Out-of-date dependencies are one of the main ways that software projects open themselves to security vulnerabilities. Closely monitoring dependencies to know when they need to be updated is an important but often forgotten task for open-source projects. Having an automated means of doing so can help turn this from a difficult chore to an easily shared test (similar to automated test suites).
However, automated dependency checks do come with wrinkles: First, updates about dependencies with security vulnerabilities need to be acted upon quickly. Otherwise, a security alert is a glaring sign saying “come take advantage of this software!” Second, the process of updating dependencies relies on good release habits within those projects. How do you know what has changed within a new version of a dependency? How do you know if any of the changes will require your own project to change? Let’s consider release management next, since it’s through release management that open-source projects can provide stability to build atop each other.
Release management
The goal of release management is to produce a new version of a software package, ready for use. For commercial software, release management can be as grand an effort as the launch of a Hollywood movie. For open-source software, release management can often be an afterthought. As with all these other practices, having a structured and consistent approach to release management can be a great benefit to an open-source project.
Release manager(s)
Who performs the work of producing a new release? For every open-source project that has grown beyond a single core contributor, it’s worth naming a release manager or a release team. This person or people will deserve credit and thanks when the work of producing new releases goes well — and when producing a new release is a challenge, the release manager/team will need sufficient authority to make decisions to resolve problems.
On the Kubernetes project, there is a “special interest group” (or SIG) focused on release management. Their responsibilities include:
- Authority to build and publish releases at the published release date under the auspices of the CNCF
- Authority to accept or reject cherrypick merge requests to the release branch
- Authority to accept or reject PRs to the kubernetes/kubernetes master branch during code slush period
- Changing the release timeline as needed if keeping it would materially impact the stability or quality of the release these responsibilities will continue to be discharged by SIG release through the Release Team. This charter grants SIG Release the following additional responsibilities
- Authority to revert code changes which imperil the ability to produce a release by the communicated date or otherwise negatively impact the quality of the release (e.g. insufficient testing, lack of documentation)
- Authority to guard code changes behind a feature flag which do not meet criteria for release
- Authority to close the submit queue to any changes which do not target the release as part of enforcing the code slush period
Note how the Kubernetes release team uses feature flags and other tools we’ve discussed previously: They act in a reactive manner, doing whatever is necessary to ship a release. This is in contrast with our previous discussion of technical steering committees (TSCs) and how they can use tools like feature flags in a proactive manner to pace development. Ideally, an open-source project is able to have both proactive planning (to build up code and features that are worthy of release) and reactive release management (to ensure that releases do happen consistently and regularly).
Release checklist
A release manager/team should have a checklist that they follow each time they “cut” a release. In the short term, this checklist helps make the process of producing a new release easier to repeat. In the long term, this checklist makes it simpler to add new members to a release team and let burnt-out members depart, without losing the “secret” steps of how to produce a release.
Release notes
Once a release has been produced, how will users understand what’s included and what changed? Ideally there is a release notes document that includes this information. It can be as simple as a bulleted list (also known as a change-log) or as thorough as an illustrated guide.
Each month, the Visual Studio Code project cuts a new release and includes illustrated release notes, which are also posted to their blog.
For the Transitland Datastore, the web application at the center of the Transitland open public-transit data platform, we use a semi-automated process to generate a change-log from GitHub issues and pull requests.
The level of detail in release notes or change-log depends in large part on the audience. Visual Studio Code’s release notes are prepared for both end-users and plug-in developers, all of whom need detail. Transitland Datastore’s change-log is prepared for other developers, who are at least somewhat familiar with the existing project and its APIs.
Semantic versioning
Typically, each software release gets a version number. The number typically increases with each release. However, there are different ways of formatting and increasing version numbers. This can serve as a signal to users of what and how much changed within the software.
Semantic Versioning (a.k.a. SemVer) is one approach to version numbers. Here’s an overview:
Given a version number MAJOR.MINOR.PATCH, increment the:
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
This signals to users that, for example, upgrading from 2.4.1 to 2.5.0 won’t require them to make any changes to their own systems. However, upgrading from 2.4.1 to 3.0.0 should only be done after reading release notes and testing the new software; a function they depend upon may have changed.
Semantic Versioning is a useful ingredient for automated dependency checks. If you trust that your dependencies are faithfully following Semantic Versioning principles, you can automatically upgrade to new releases that just increment the “minor” or “patch” version number. Ideally, your project is also using automated acceptance tests, in order to catch any unexpected side effects that arise from upgrading a dependency.
LTS (long-term support) versioning
Even if there are advantages to users in upgrading software as soon as possible, there are also costs. Some users will never be able to keep up with the latest version of a project, and may still have support needs and questions about their outdated versions.
One way out of such situations is to label certain releases as having long-term support (or LTS). LTS releases will be maintained and support for a longer time than other releases. Bug fixes and security fixes made in future releases may also be “backported” so that they are also available to users of an LTS release.
The Ubuntu operating system project releases new versions every 9 months. Every 2 years, one of these releases is marked as an LTS release. This LTS release is supported for 5 years.
“Train” release cycles
What should actually go into a release? That question is quite dependent on project specifics. Some projects actually try to avoid answering the question. Instead they set up a “train” release cycle, where releases happen on a consistent schedule. Whatever functionality is ready to release when the next date arrives is included in that release.
Here’s an illustration of how the EmberJS framework releases beta and stable versions every 6 weeks:

Codes of conduct
Our discussion of release management hinted at some of the problems that can arise in open-source projects. For example: disagreement over features that make it into a release, or unexpected problems merging together code from multiple contributors. Our discussion of technical steering committees also hinted at the challenges of many people working together on a complex technical project. In the short term, tempers can flare. In the long term, projects can become exclusive clubs, inadvertently sending signals to potential contributors that they are not welcome.
These days, every open-source project should seriously consider adopting a code of conduct. It’s a proactive means of welcoming new contributors, and it’s a means of providing some “guardrails” for existing contributors to keep in mind.
The following codes of conduct are widely used and referenced:
“The roadmap”
So far we’ve avoided mentioning the “roadmap.” A roadmap is a forward-looking plan, ordering the development of new functionality and assigning dates to future releases. Developers often find the process of writing roadmaps to be fun and inspiring — the focus is on the potential of tomorrow, rather than the bug fixes or the maintenance tasks of today. Users often find that reading roadmaps provides clarity and confidence — the roadmap tells them what further functionality they can expect, if they invest in committing to use a software package. However, a roadmap does not necessarily represent reality. Projects that are regularly unable to meet their self-imposed targets can lose whatever inspiration and clarity were generated by publishing a roadmap.
By committing to a firm roadmap, open-source projects can also give up some of their room for flexibility that can be a useful advantage. Open-source projects are often more engineering-driven than proprietary projects. That is, developers and designers who are “closer to the code” are responsible for more decision making. This may provide more opportunities for unexpected optimizations and creativity during implementation. Roadmaps that are overly detailed can hinder opportunistic creation of new functionality and refactoring.
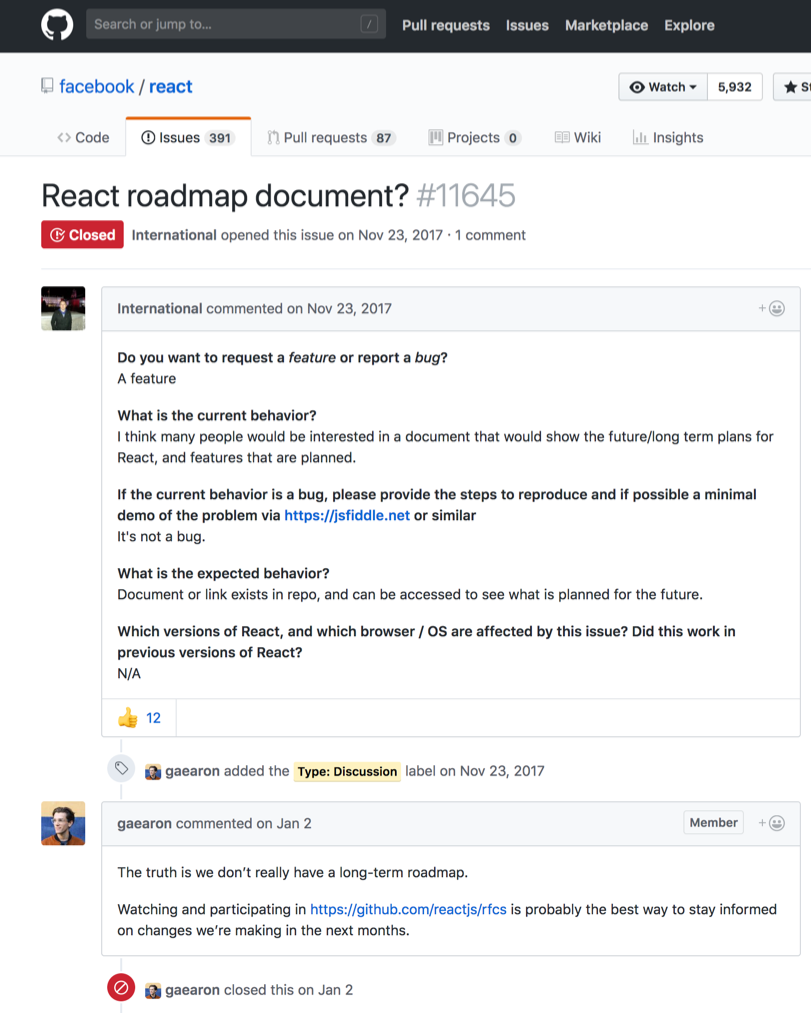
In reaction to these shortcomings, some open-source projects never write roadmaps. For example, the ReactJS framework:
Some projects use “train” release cycles to effectively replace roadmaps. For example, on the Django project, whatever additions are completed by a certain date are considered part of the “roadmap” for a release:

Finally, some projects find a mid-point. They may use a roadmap to define major themes for future releases, but avoid providing fine details about implementation and functionality that will likely be subject to change. They may use a roadmap to order development priorities and releases, but avoid attaching specific dates. They may use a roadmap to help divide duties among multiple organizations for release management and other maintenance tasks, but avoid listing any further goals for each release.
When writing roadmaps, it’s too easy to be overconfident in the future of an open-source project. Before committing to a roadmap, consider if some of the other practices we’ve discussed could help achieve similar goals, with more room for flexibility along the way. After considering other practices, if there are still questions that remain that would be best answered by a roadmap-style plan, start with your roadmap only providing a “skeleton” for the most important aspects of the project to plan out in advance.
“The eternal rewrite”
We’ve discussed many positive practices of open-source projects. Let’s end by considering some unfortunate outcomes.
First, consider how many open-source projects encounter problems during major version transitions. A 2.0 release promises to fix all current problems and provide great improvements. But 2.0 still hasn’t arrived, so users continue to work with and improve 1.0 in the meantime. Bug reports keep arriving on 1.0, distracting developers from completing 2.0. It’s unclear what version new users should use, and there are no clear ways for new contributors to help.
Unfortunately this is what’s happened to the ActiveModelSerializers project, with parallel 0.8, 0.9, and 0.10 versions in various states of usage and completion:
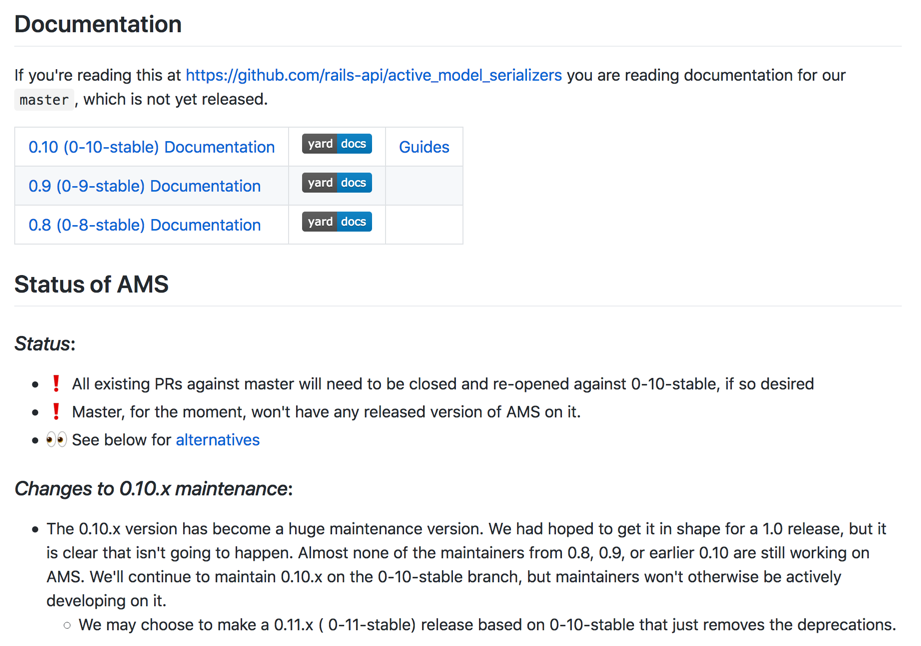
Consider “the eternal rewrite” situation. What of the practices that we discussed could help a project avoid this fate? What of the practices could help a project like this recover and move forward? (As they say in math textbooks, we’ll leave this as an exercise to the reader.)
“The big switchover”
Another unfortunate outcome to consider for a version change: “the big switchover.” That is, the new version is available, but major changes leave a large portion of the user community behind.
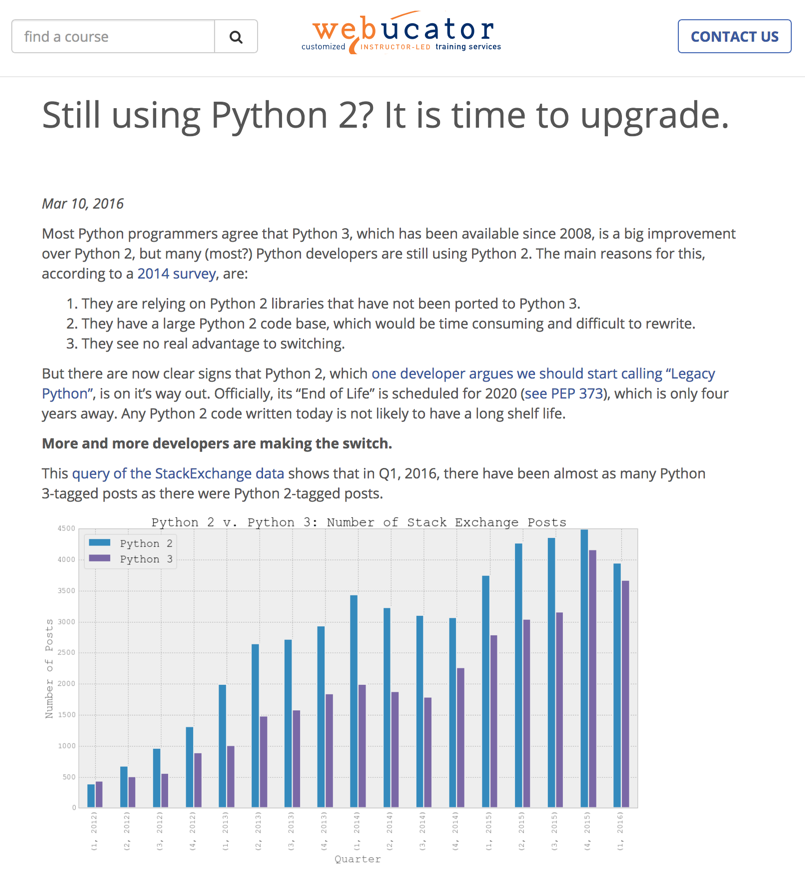
For example, this is effectively a decade-long process for users and developers to switch from Python 2.x to 3.x:
For the Angular project, 1.x and 2.x were so different that some users and developers have never made the leap and continue on 1.x, as if it were a completely different project:

“The big switchover” is a good problem to have. It means that a project is so widely used that it has entrenched users. Then again, it may also show a lack of applying some of the open-source practices that we discussed previously. How could a project have better engaged its users, its contributors, and its organizers in the process of building and migrating to a new version?
A holistic view of open-source
For a blog post about open-source software, we’ve talked surprisingly little about software engineering or about the business of software. That’s by design. There’s lots to read online about software engineering (The users of Stackoverflow will try to answer most any question you have). There’s also lots to read about the business of open-source software (even if it’s grand-standing when describing successes and similarly overconfident when judging failures).
What is often missing are recipes for how to organize and scale open-source projects that have had enough success to get into trouble. That is, projects like OpenTripPlanner that have many users and interested contributors, but a lack of structure to take full advantage of that attention and channel it toward sustainable growth and maintenance. Software does still need to get written, and individuals and organizations do need to earn their income — however, those are necessary but not sufficient ingredients for project success.
At Interline, we depend upon many open-source projects to succeed. Our clients do, too. That’s why we take this holistic view when evaluating, advising, and contributing to open-source projects. We think it helps improve the odds of success for an open-source project, beyond just code and cash.